Imagine you have an array of booleans (or an array of ‘conditions’), and you want to pack it - so you use only one bit per boolean. How to do it? Let’s do some experiments!
Motivation
I started writing this post because I came across a similar problem during my work some time ago. The code in one area of our system packed boolean results of a condition into bits. I wondered if I could optimize that process. This ‘algorithm’ is not a rocket science, but as usually, it opened a whole box of details and interesting solutions. So I decided to share it with my readers.
To illustrate the problem, we might think about an image in greyscale. We want to generate another image that has only two colors: white or black; we use a threshold value to distinguish between white and black color from the input image.
outputColor[x][y] = inputColor[x][y] > Threshold;
The input has some integer range (like 0…255), but the output is boolean: true/false.
Like here, image thresholding:

Then we want to pack those boolean values into bits so that we save a lot of memory. If bool is implemented as 8bit unsigned char, then we can save 7/8 of memory!
For example, instead of using 128kb for 256x512 greyscale image, we can now use 16kb only.
256 X 512 = 131072 (bytes) = 128kb
131072/8 = 16384 (bytes) = 16kb
Should be simple to code… right?
The algorithm
To make things clear let’s make some initial assumptions:
- input:
- array of integer values
- length of the array: N
- threshold value
- output:
- array of BYTES of the length M
- M - number of bytes needed to write N bits
- i-th bit of the array is set when inputArray[i] > threshold.
Brief pseudo code
for i = 0...N-1
byte = pack (input[i] > threshold,
input[i+1] > threshold,
...,
input[i+7] > threshold)
output[i/8] = byte
i+=8
// handle case where N not divisible by 8
Alternatively, we might remove the threshold value and just take input array of booleans (so there won’t be any need to make comparisons).
Drawbacks of packing
Please note that I only focused on the ‘packing’ part. With the packed format you save memory, but there are more instructions to unpack a value. Sometimes this additional processing might cause the slow-down of the whole process! Always measure measure measure because each case might be different!
This problem is similar to compression algorithms, although packing is usually much faster process. As always, there’s a conflict between the storage and the computation power (Space–time tradeoff).
The benchmark
I want to compare several implementations:
- std::bitset
- std::vector of bools
- one ‘manual’ version
- second ‘manual’ version
Plus, the next time we’ll also add parallel options…
For the benchmarking library, I decided to use Celero. You can find more details about using it in my post about Benchmarking Libs for C++.
With Celero there’s an easy way to express different options for the benchmark. So for example, I’d like to run my code against different sizes of the input array: like 100k, 200k, … Also, there’s a clean way to provide setUp/tearDown methods that will be invoked before each run.
The base fixture provides input array:
inputValues.reset(newint[N]);
referenceValues.reset(newbool[N]);
arrayLength = N;
//Standard mersenne_twister_engine seeded with 0, constant
std::mt19937 gen(0);
std::uniform_int_distribution<> dist(0,255);
// set every byte
for(int64_t i =0; i < experimentValue;++i)
{
inputValues[i]= dist(gen);
referenceValues[i]= inputValues[i]>ThresholdValue;
}std::bitset<N>
OK, this version will be really simple, take a look:
for(int64_t i =0; i < arrayLength;++i)
outputBitset.set(i, inputValues[i]>ThresholdValue);The only drawback of using bitset is that it requires compile time N constant. Also, bitset is implementation specific, so we’re not sure how the memory is laid out internally. I would reject this version from the final production code, but it’s useful as a baseline.
For example, here’s the fixture for this baseline benchmark:
classStdBitsetFixture:publicCompressBoolsFixture
{
public:
virtualvoid tearDown()
{
for(int64_t i =0; i < arrayLength;++i)
Checker(outputBitset[i], referenceValues[i], i);
}
std::bitset<MAX_ARRAY_LEN> outputBitset;
};In tearDown we check our generated values with the reference - Checker just checks the values and prints if something is not equal.
std::vector<bool>
Another simple code. But this time vector is more useful, as it’s dynamic and the code is still super simple.
for(int64_t i =0; i < arrayLength;++i)
outputVector[i]= inputValues[i]>ThresholdValue;And the fixture:
classStdVectorFixture:publicCompressBoolsFixture
{
public:
virtualvoid setUp(int64_t experimentValue) override
{
CompressBoolsFixture::setUp(experimentValue);
outputVector.resize(experimentValue);
}
virtualvoid tearDown()
{
for(int64_t i =0; i < arrayLength;++i)
Checker(outputVector[i], referenceValues[i], i);
}
std::vector<bool> outputVector;
};This time, we generate the vector dynamically using experimentValue (N - the size of the array).
Still, vector<bool> might not be a good choice for the production code; see 17.1.1 Do not use std::vector | High Integrity C++ Coding Standard.
Manual version
The first two versions were just to start with something, let’s now create some ‘real’ manual code :)
I mean ‘manual’ since all the memory management will be done but that code. Also, there won’t be any abstraction layer to set/get bits.
The setup looks like this:
virtualvoid setUp(int64_t experimentValue) override
{
CompressBoolsFixture::setUp(experimentValue);
numBytes =(experimentValue +7)/8;
numFullBytes =(experimentValue)/8;
outputValues.reset(newuint8_t[numBytes]);
}outputValue is just a unique_ptr to array of uint8_t. We have N/8 full bytes and also there’s one at the end that might be partially filled.
The first case will use just one variable to build the byte. When this byte is complete (8 bits are stored), we can save it in the output array:
uint8_tOutByte=0;
int shiftCounter =0;
auto pInputData = inputValues.get();
auto pOutputByte = outputValues.get();
for(int64_t i =0; i < arrayLength;++i)
{
if(*pInputData >ThresholdValue)
OutByte|=(1<< shiftCounter);
pInputData++;
shiftCounter++;
if(shiftCounter >7)
{
*pOutputByte++=OutByte;
OutByte=0;
shiftCounter =0;
}
}
// our byte might be incomplete, so we need to handle this:
if(arrayLength &7)
*pOutputByte++=OutByte;Improvement
The first manual version has a little drawback. As you see, there’s only one value used when doing all the computation. This is quite inefficient as there’s little use of instruction pipelining.
So I came up with the following idea:
uint8_tBits[8]={0};
constint64_t lenDivBy8 =(arrayLength /8)*8;
auto pInputData = inputValues.get();
auto pOutputByte = outputValues.get();
for(int64_t i =0; i < lenDivBy8; i +=8)
{
Bits[0]= pInputData[0]>ThresholdValue?0x01:0;
Bits[1]= pInputData[1]>ThresholdValue?0x02:0;
Bits[2]= pInputData[2]>ThresholdValue?0x04:0;
Bits[3]= pInputData[3]>ThresholdValue?0x08:0;
Bits[4]= pInputData[4]>ThresholdValue?0x10:0;
Bits[5]= pInputData[5]>ThresholdValue?0x20:0;
Bits[6]= pInputData[6]>ThresholdValue?0x40:0;
Bits[7]= pInputData[7]>ThresholdValue?0x80:0;
*pOutputByte++=Bits[0]|Bits[1]|Bits[2]|Bits[3]|
Bits[4]|Bits[5]|Bits[6]|Bits[7];
pInputData +=8;
}
if(arrayLength &7)
{
autoRestW= arrayLength &7;
memset(Bits,0,8);
for(longlong i =0; i <RestW;++i)
{
Bits[i]=*pInputData ==ThresholdValue?1<< i :0;
pInputData++;
}
*pOutputByte++=Bits[0]|Bits[1]|Bits[2]|Bits[3]|Bits[4]|Bits[5]|Bits[6]|Bits[7];
}What happened here?
Instead of working on one variable I used eight different variables where we store the result of the condition. However, there’s still a problem when doing that large OR. For now, I don’t know how to improve it. Maybe you know some tricks? (without using SIMD instructions…)
Results
Was I right with this approach of using more variables? Let’s see some evidence!
Intel i7 4720HQ, 12GB Ram, 512 SSD, Windows 10.
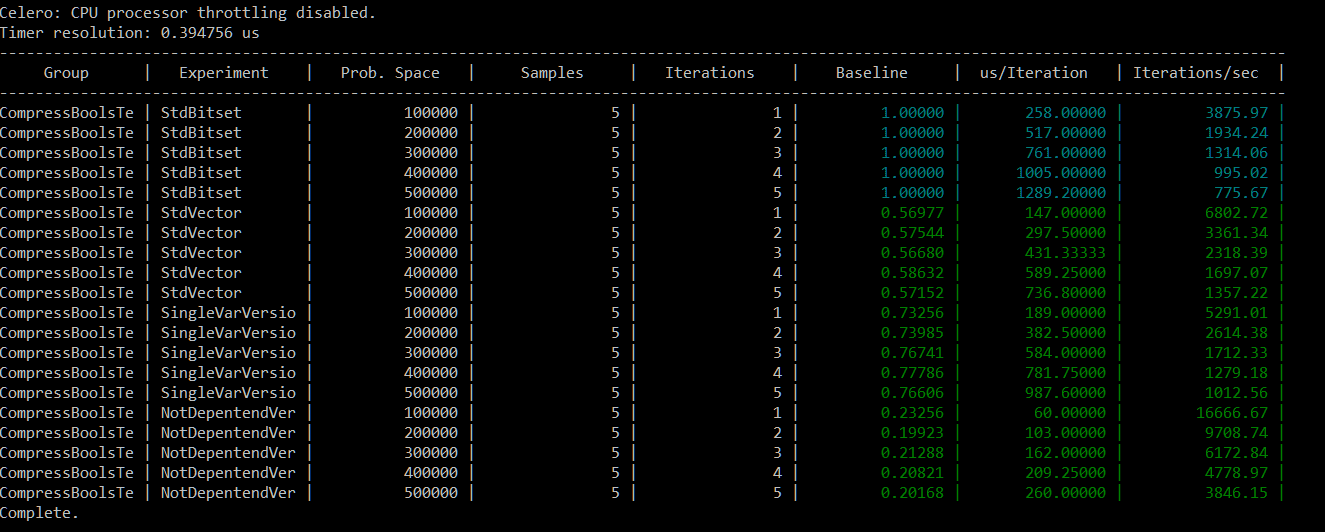
The optimized version (using separate variables) is roughly 5x faster that bitset and almost 3.5x faster than the first manual version!
The chart:
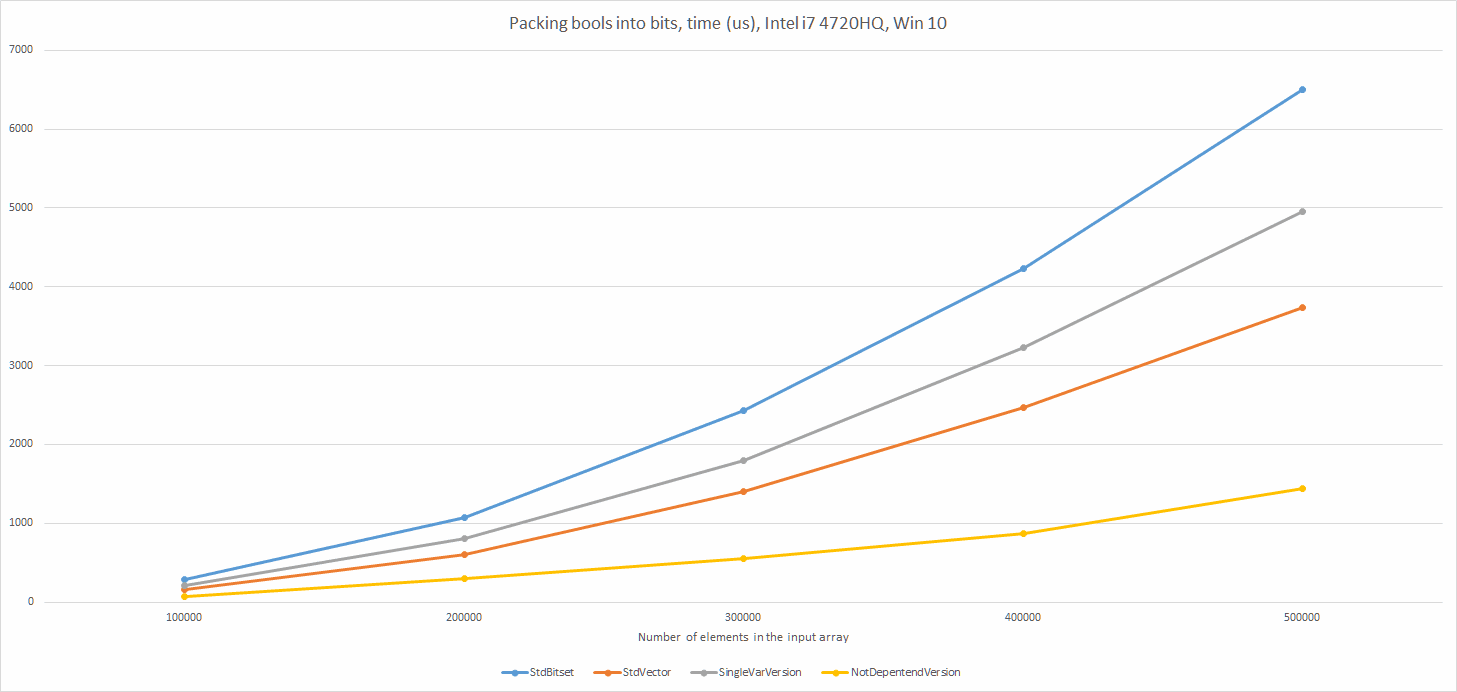
Summary
The experiment was not so hard… so far! It was a good exercise for writing benchmarks.
What can we see from the results? The first manual version was still better than the std::bitset, but worse than std::vector. Without looking at the traces, profiles I optimized it by using more variables to compute the conditions. That way there was less data dependency and CPU could perform better.
Next time I’ll try to parallelize the code. How about using more threads or vector instructions? For example, I’ve found a really interesting instruction called: _mm_movemask_epi8… See you next week.
code on github: fenbf/celeroTest/celeroCompressBools.cpp