
In one of my previous post I wrote about performance differences between using vector<Obj> and vector<shared_ptr<Obj>>. Somehow I knew that the post is a bit unfinished and need some more investigation.
This time I will try to explain memory access patterns used in my code and why performance is lost in some parts.
Content
- Recap
- The test code
- The results
- Memory access pattern
- Conclusion
Recap
I've compared the following cases:
std::vector<Object>- memory is allocated on the heap but vector guarantees that the mem block is continuous. Thus, iteration over it should be quite fast. See below to see why it should be fast.

std::vector<std::shared_ptr<Object>>- this simulates array of references from C#. You have an array, but each element is allocated in a different place in the heap.- update Although my code allocated hundreds of shared pointers they almost looked like single block of memory! I've allocated space one after another, thus memory allocator simply choose next free memory cell that was actually quite close to the previous one.

The Test code
Full repository can be found here: github/fenbf/PointerAccessTest
The test code:
- creates a desired container of objects
- runs generate method one time
- runs update method N times
Vector of Pointers:
// start measuring time for Creation
std::vector<std::shared_ptr<Particle>> particles(count);
for (auto &p : particles)
p = std::make_shared<Particle>();
// end time measurment
// >>>>>>
// randomize:
for (size_t i = 0; i < count / 2; ++i)
{
int a = rand() % count;
int b = rand() % count;
if (a != b)
std::swap(particles[a], particles[b]);
}
// >>>>>>
for (auto &p : particles)
p->generate();
// start measuring time for Update
for (size_t u = 0; u < updates; ++u)
{
for (auto &p : particles)
p->update(1.0f);
}
// end time measurment
Please notice that the above code was enhanced with randomize section. This code creates a fragmentation in the memory. It tries to simulates some real life scenario where objects might be created/deleted not in different moments. Instead of that we could create X pointers, then delete some of them, allocate some other objects, allocate then the rest... just to make allocator not create space close to each other.
I would like to thank Morten Bendiksen for this idea from his comments!
Before the randomize, we could get the following pointers' addresses:
| adress | difference |
|---|---|
| 16738564 | 0 |
| 16712876 | -25688 |
| 16712972 | 96 |
| 16768060 | 55088 |
| 16768156 | 96 |
| 16768252 | 96 |
| 16768348 | 96 |
| 16768444 | 96 |
| 16768540 | 96 |
| 16768636 | 96 |
| 16768732 | 96 |
| 16768828 | 96 |
| 16768924 | 96 |
| 16770404 | 1480 |
| 16770212 | -192 |
| 16769444 | -768 |
| 16769252 | -192 |
| 16770020 | 768 |
| 16769540 | -480 |
| 16769348 | -192 |
| 16769636 | 288 |
The first table is not a single block of memory, but still the distance to the neighbour particles is usually not that huge. In my last post there was something like 8% of loss os using such pattern.
After randomize:
| adress | difference |
|---|---|
| 14772484 | 0 |
| 14832644 | 60160 |
| 14846956 | 14312 |
| 14876972 | 30016 |
| 14802076 | -74896 |
| 14802172 | 96 |
| 14809916 | 7744 |
| 14858572 | 48656 |
| 14875628 | 17056 |
| 14816612 | -59016 |
| 14819756 | 3144 |
| 14822996 | 3240 |
| 14802844 | -20152 |
| 14804612 | 1768 |
| 14803364 | -1248 |
| 14813252 | 9888 |
| 14803556 | -9696 |
| 14844268 | 40712 |
| 14906900 | 62632 |
| 14815460 | -91440 |
| 14861164 | 45704 |
On the other hand, the second table shows huge distances between neighbour objects. They are very random and hardware prefetcher cannot cope with this pattern.
Vector of Objects:
// start measuring time for Creation
std::vector<Particle> particles(count);
// end time measurment
for (auto &p : particles)
p.generate();
// start measuring time for Update
for (size_t u = 0; u < updates; ++u)
{
for (auto &p : particles)
p.update(1.0f);
}
// end time measurment
This time randomization of course has no sense :)
The results
- Core i5 2400, Sandy Bridge
- Visual Studio 2013 for Desktop Express
- Release Mode, /fp:fast, /arch:SSE2, /O2


Memory access pattern
The most important thing about the memory is the "latency"
Recently there was a great picture explaining it:
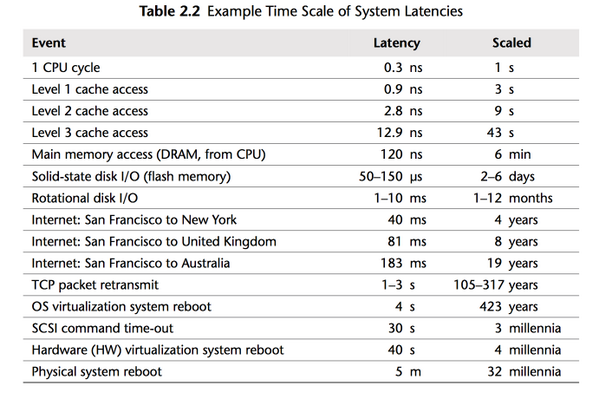
In general having data already in cache is a great thing. When some variable needs to be loaded from the main memory, then we need to wait. We definitely do not want to wait too long for the data.
So, why it is so important to care about iterating over continuous block of memory?
Let us look at out main loop:
for each particle p:
p->update(DELTA_TIME);
The Continuous Case
- Before we can update any fields of the first particle it has to be fetched from the maim memory into cache/registers. Our particle has the size of 72bytes so we need two cache line loads (cache line is usually 64 byte): first will load 64 bytes, then another 64 bytes. Notice that only the first 8 bytes from the second load are used for the first particle. The rest - 56b - are the bytes of the second particle.
- In the second step we have already 56 bytes of the second particle, so we need another load - 64 bytes - to get the rest. This time we also get some data of the third particle.
- And the patterns repeat...

For 1000 particles we need 1000*72bytes = 72000 bytes, that means 72000/64 = 1125 cache line loads. In other words for each particle we will need 1.125 cache line reads.
But CPU is quite smart and will additionally use thing called Hardware Prefetcher. CPU will detect that we operate on one huge memory block and will prefetch some of the cache lines before we even ask. Thus instead of waiting for the memory it will be already in the cache!
What about the case with vector of pointers?
The pointer Case
- load data for the first particle. Two cache line reads.
- load data for the second particle. Uups... this time we cannot use data loaded in the second cache line read (from the first step), because second particle data is located somewhere else in the memory!So for the second particle we need also 2 loads!
- the patters repeat...
For 1000 particles we need on the average 2000 cache line reads! This is 78% more cache line reads than the first case! Additionally Hardware Prefetcher cannot figure out the pattern - it is random - so there will be a lot of cache misses and stalls.
In our experiment the pointer code for 80k of particles was more 266% slower than the continuous case.
Conclusion
The test showed that memory access pattern are the crucial thing in optimized code. Just by moving data around, by carefully storing it in one place, we can get huge performance speed up. Another thing to notice is that sometimes we are, simply, not aware of memory space - we might think that the language/compiler/runtime will take care of everything.