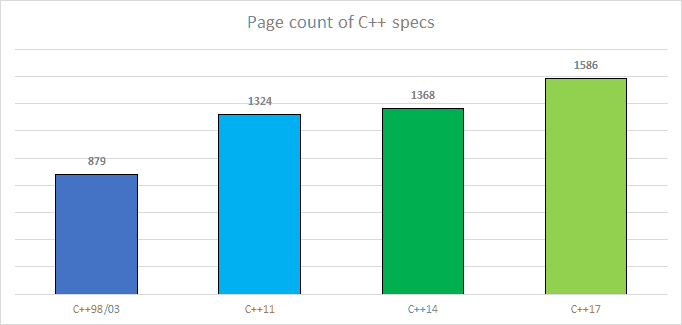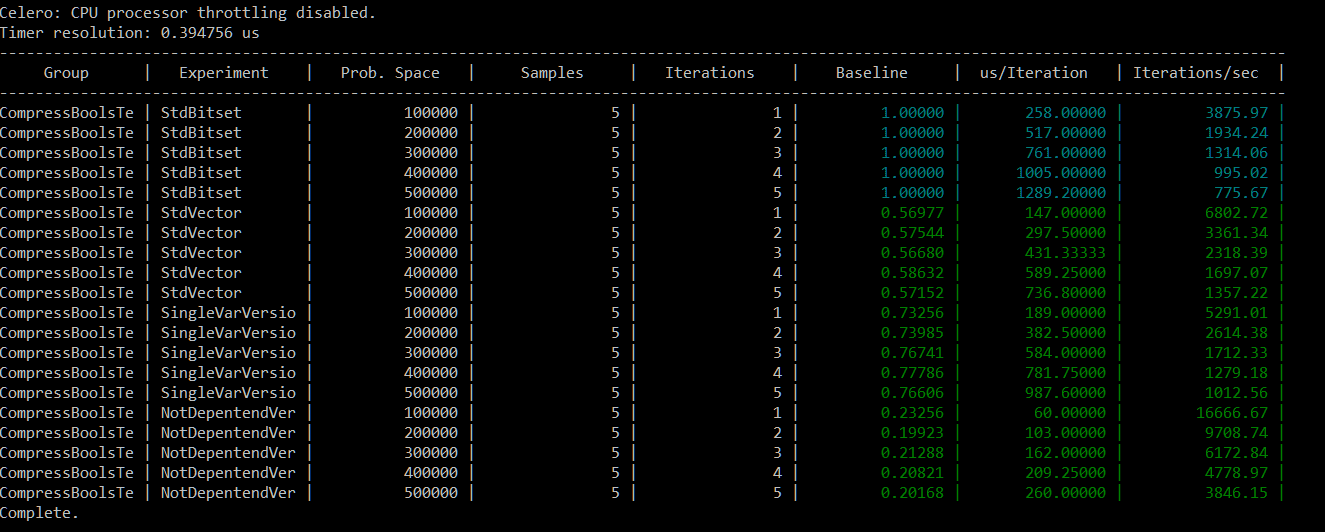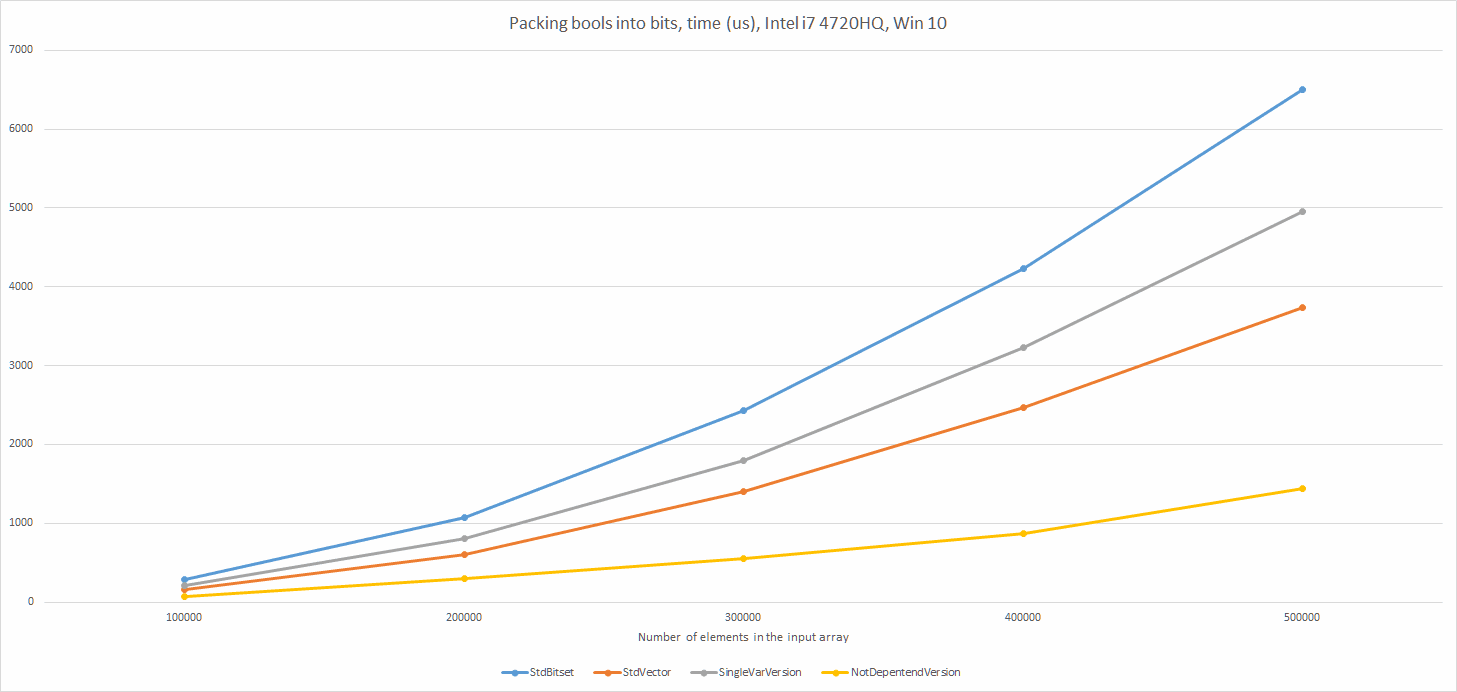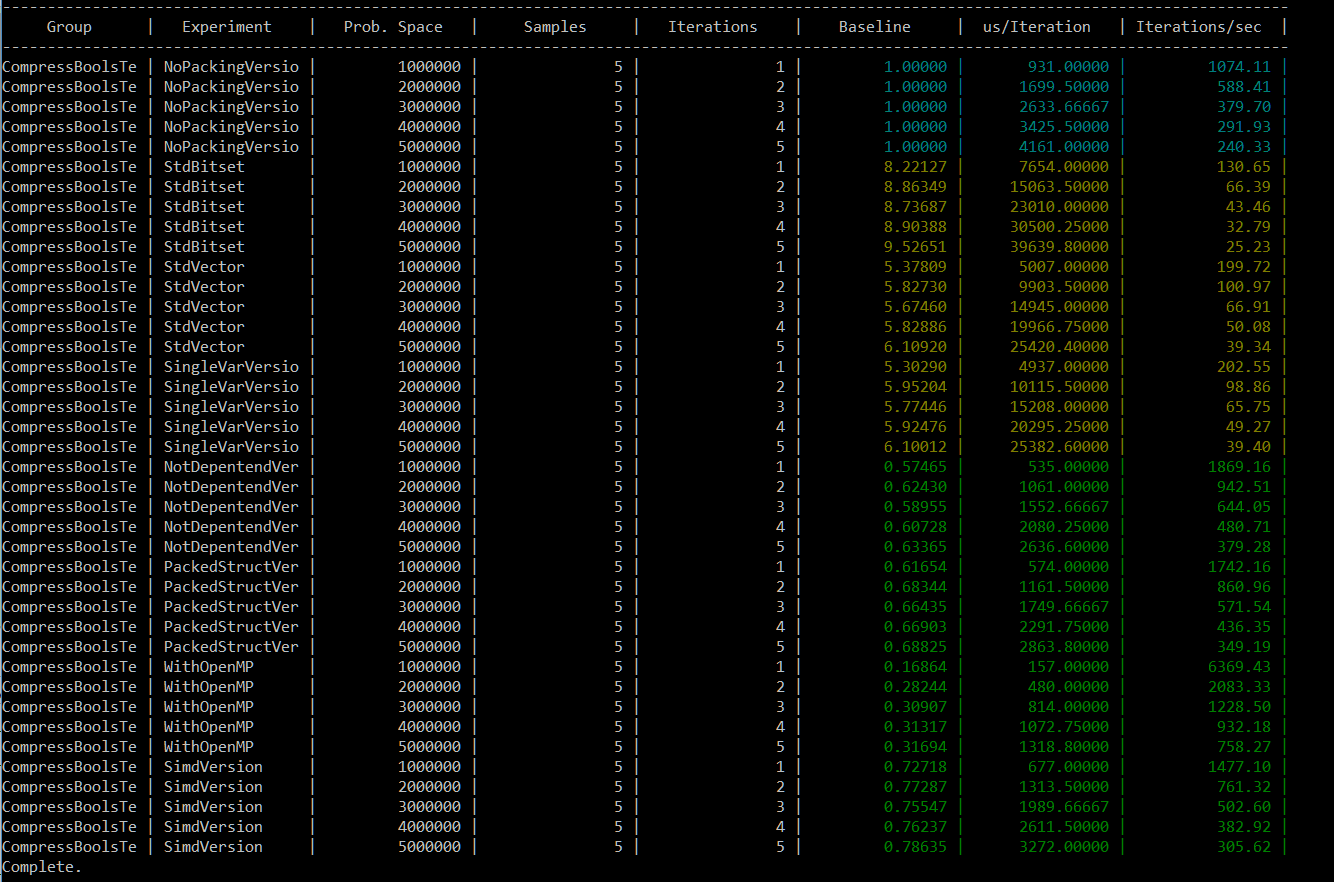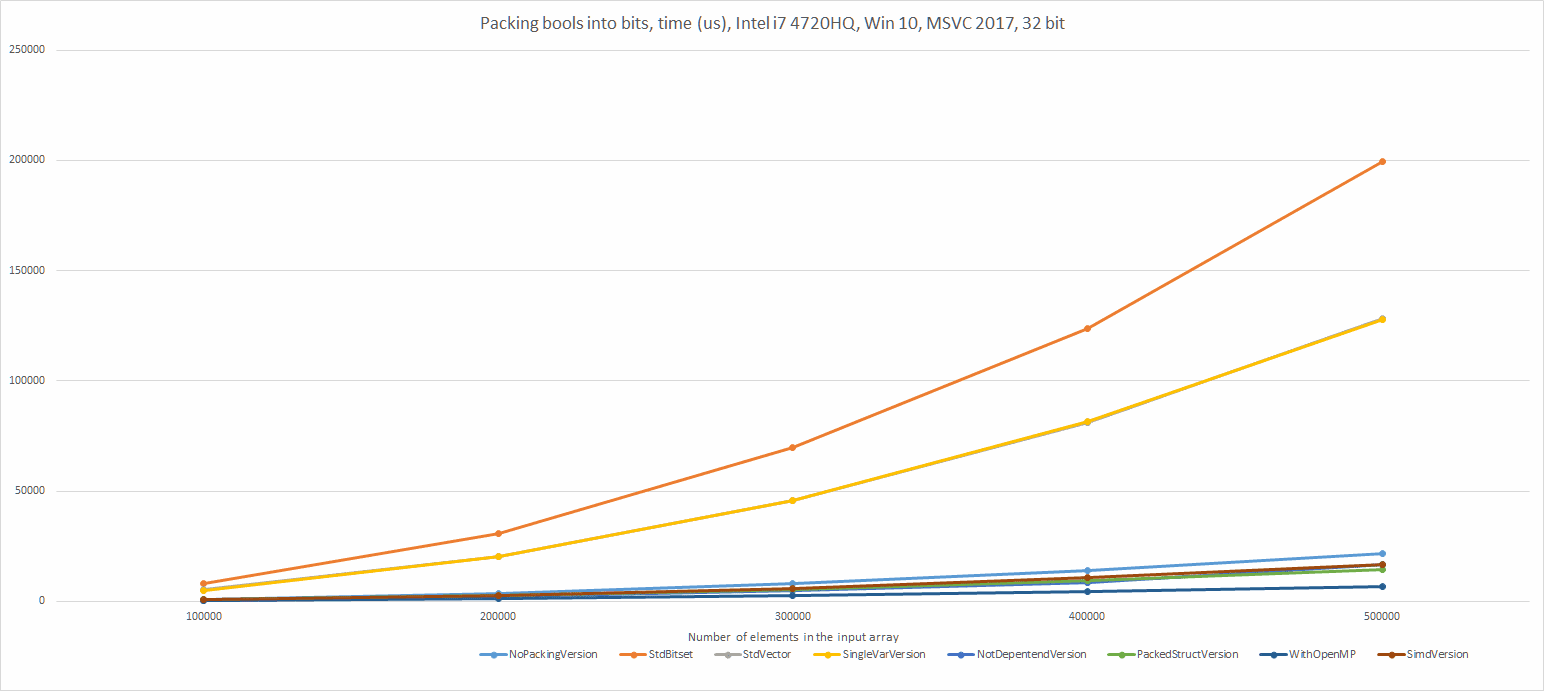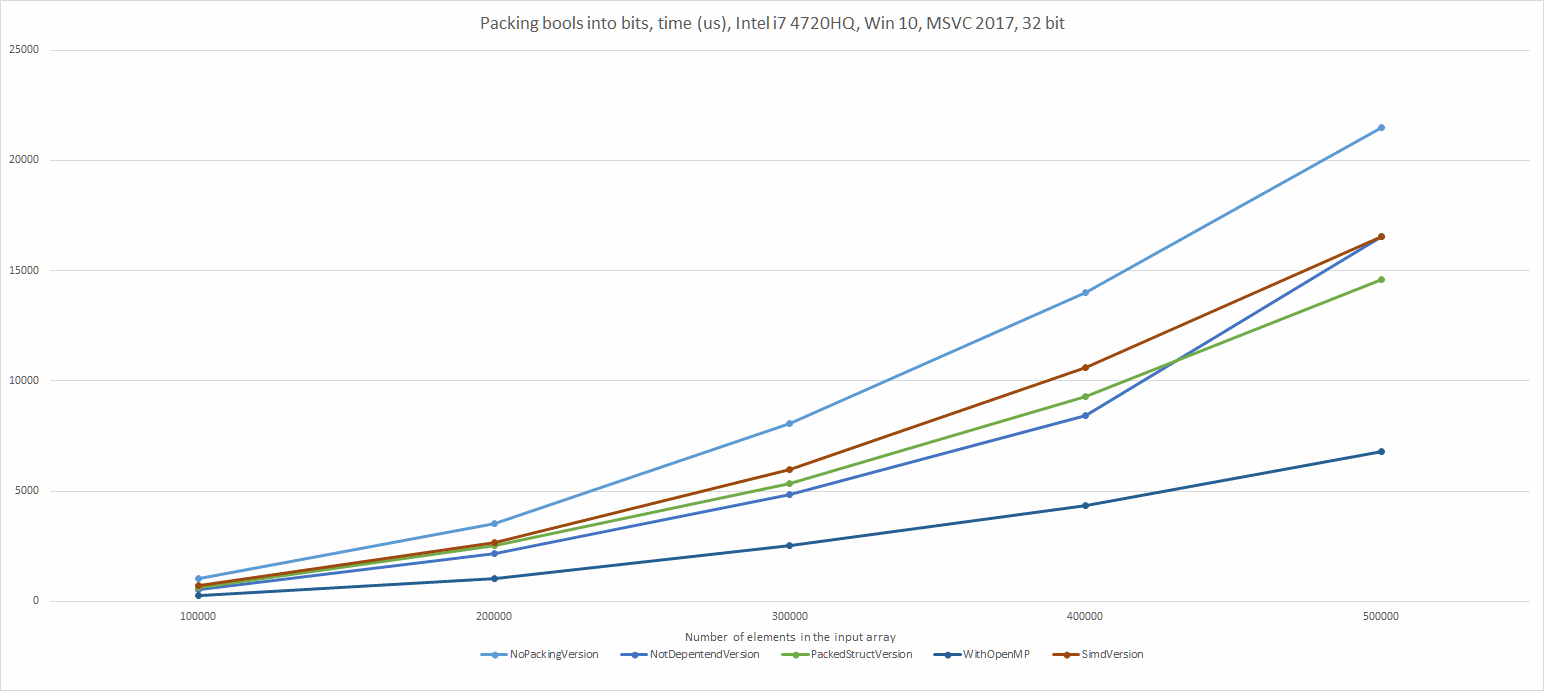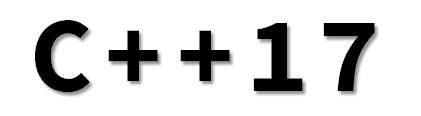
In my last C++ summary (for 2016) I wrote that the draft for C++17 is the most important thing that happened. I’ve put a list of features of the new standard, and today I’d like to expand the topic so we can learn some more details.
- Intro
- Language Features
- New auto rules for direct-list-initialization
- static_assert with no message
- typename in a template template parameter
- Removing trigraphs
- Nested namespace definition
- Attributes for namespaces and enumerators
- u8 character literals
- Allow constant evaluation for all non-type template arguments
- Fold Expressions
- Remove Deprecated Use of the register Keyword
- Remove Deprecated operator++(bool)
- Removing Deprecated Exception Specifications from C++17
- Make exception specifications part of the type system
- Aggregate initialization of classes with base classes
- Lambda capture of *this
- Using attribute namespaces without repetition
- Dynamic memory allocation for over-aligned data
- Unary fold expressions and empty parameter packs
- __has_include in preprocessor conditionals
- Template argument deduction for class templates
- Non-type template parameters with auto type
- Guaranteed copy elision
- New specification for inheriting constructors (DR1941 et al)
- Direct-list-initialization of enumerations
- Stricter expression evaluation order
- constexpr lambda expressions
- Differing begin and end types in range-based for
- [[fallthrough]] attribute
- [[nodiscard]] attribute
- [[maybe_unused]] attribute
- Ignore unknown attributes
- Pack expansions in using-declarations
- Decomposition declarations
- Hexadecimal floating-point literals
- init-statements for if and switch
- Inline variables
- DR: Matching of template template-arguments excludes compatible templates
- std::uncaught_exceptions()
- constexpr if-statements
- Library Features
- Contributors
- Summary
Intro
Work in Progress! I am happy to see your help with the list! :)
9 descriptions missing out of 39! Plus all from library changes
Updated: This post was updated at 8am, 13th January 2017.
If you have code examples, better explanations or any ideas, let me know! I am happy to update the current post so that it has some real value for others.
The plan is to have a list of features with some basic explanation, little example (if possible) and some additional resources, plus a note about availability in compilers. Probably, most of the features might require separate articles or even whole chapters in books, so the list here will be only a jump start.
See this github repo: github/fenbf/cpp17features. Add a pull request to update the content.
The list comes from the following resources:
- SO: What are the new features in C++17?
- cppreference.com/C++ compiler support.
- AnthonyCalandra/modern-cpp-features cheat sheet - unfortunately it doesn’t include all the features of C++17.
- plus other findings and mentions
And onf of the most important resource: Working Draft, Standard for Programming Language C++
Language Features
New auto rules for direct-list-initialization
| GCC: 5.0 | Clang: 3.8 | MSVC: 14.0 |
|---|
Fixes some cases with auto type deduction. The full background can be found in Auto and braced-init-lists, by Ville Voutilainen.
It fixes the problem of deducing std::initializer_list like:
auto x = foo();// copy-initialization
auto x{foo};// direct-initialization, initializes an initializer_list
int x = foo();// copy-initialization
int x{foo};// direct-initializationAnd for the direct initialization, new rules are:
- For a braced-init-list with only a single element, auto deduction will deduce from that entry;
- For a braced-init-list with more than one element, auto deduction will be ill-formed.
Basically, auto x { 1 }; will be now deduced as int, but before it was an initializer list.
static_assert with no message
| GCC: 6.0 | Clang: 2.5 | MSVC: 15.0 preview 5 |
|---|
Self-explanatory. It allows just to have the condition without passing the message, version with the message will also be available. It will be compatible with other asserts like BOOST_STATIC_ASSERT (that didn’t take any message from the start).
typename in a template template parameter
| GCC: 5.0 | Clang: 3.5 | MSVC: 14.0 |
|---|
Allows you to use typename instead of class when declaring a template template parameter. Normal type parameters can use them interchangeably, but template template parameters were restricted to class, so this change unifies these forms somewhat.
template<template<typename...>typenameContainer>
// used to be invalid ^^^^^^^^
struct foo;
foo<std::vector> my_foo;Removing trigraphs
| GCC: 5.1 | Clang: 3.5 | MSVC: Yes |
|---|
Removes ??=, ??(, ??>, …
Makes the implementation a bit simpler, see MSDN Trigraphs
Nested namespace definition
| GCC: 6.0 | Clang: 3.6 | MSVC: 14.3 |
|---|
Allows to write:
namespace A::B::C {
//…
}Rather than:
namespace A {
namespace B {
namespace C {
//…
}
}
}Attributes for namespaces and enumerators
| GCC: 4.9 (namespaces)/ 6 (enums) | Clang: 3.4 | MSVC: 14.0 |
|---|
Permits attributes on enumerators and namespaces. More details in N4196.
enum E {
foobar =0,
foobat [[deprecated]]= foobar
};
E e = foobat;// Emits warning
namespace[[deprecated]] old_stuff{
void legacy();
}
old_stuff::legacy();// Emits warningu8 character literals
| GCC: 6.0 | Clang: 3.6 | MSVC: 14.0 |
|---|
UTF-8 character literal, e.g.
u8'a'. Such literal has typecharand the value equal to ISO 10646 code point value of c-char, provided that the code point value is representable with a single UTF-8 code unit. If c-char is not in Basic Latin or C0 Controls Unicode block, the program is ill-formed.
The compiler will report errors if character cannot fit inside u8 ASCII range.
Reference:
- cppreference.com/character literal
- SO: What is the point of the UTF-8 character literals proposed for C++17?
Allow constant evaluation for all non-type template arguments
| GCC: 6.0 | Clang: 3.6 | MSVC: not yet |
|---|
todo…
Fold Expressions
| GCC: 6.0 | Clang: 3.6 | MSVC: not yet |
|---|
More background here in P0036
Articles:
Remove Deprecated Use of the register Keyword
| GCC: 7.0 | Clang: 3.8 | MSVC: not yet |
|---|
The register keyword was deprecated in the 2011 C++ standard. C++17 tries to clear the standard, so the keyword is now removed.
Remove Deprecated operator++(bool)
| GCC: 7.0 | Clang: 3.8 | MSVC: not yet |
|---|
The ++ operator for bool was deprecated in the original 1998 C++ standard, and it is past time to remove it formally.
Removing Deprecated Exception Specifications from C++17
| GCC: 7.0 | Clang: 4.0 | MSVC: not yet |
|---|
Dynamic exception specifications were deprecated in C++11. This paper formally proposes removing the feature from C++17, while retaining the (still) deprecated throw() specification strictly as an alias for noexcept(true).
Make exception specifications part of the type system
| GCC: 7.0 | Clang: 4.0 | MSVC: not yet |
|---|
Previously exception specifications for a function didn’t belong to the type of the function, but it will be part of it.
We’ll get an error in the case:
void(*p)()throw(int);
void(**pp)() noexcept =&p;// error: cannot convert to pointer to noexcept functionAggregate initialization of classes with base classes
| GCC: 7.0 | Clang: 3.9 | MSVC: not yet |
|---|
If a class was derived from some other type you couldn’t use aggregate initialization. But now the restriction is removed.
struct base {int a1, a2;};
struct derived : base {int b1;};
derived d1{{1,2},3};// full explicit initialization
derived d1{{},1};// the base is value initializedTo sum up: from the standard:
An aggregate is an array or a class with:
* no user-provided constructors (including those inherited from a base class),
* no private or protected non-static data members (Clause 11),
* no base classes (Clause 10) and // removed now!
* no virtual functions (10.3), and
* no virtual, private or protected base classes (10.1).
Lambda capture of *this
| GCC: 7.0 | Clang: 3.9 | MSVC: not yet |
|---|
this pointer is implicitly captured by lambdas inside member functions. Member variables are always accessed by this pointer.
Example:
struct S {
int x ;
void f(){
// The following lambda captures are currently identical
auto a =[&](){ x =42;}// OK: transformed to (*this).x
auto b =[=](){ x =43;}// OK: transformed to (*this).x
a();
assert( x ==42);
b();
assert( x ==43);
}
};Now you can use *this when declaring a lambda, for example auto b = [=, *this]() { x = 43 ; }. That way this is captured by value. Note that the form [&,this] is redundant but accepted for compatibility with ISO C++14.
Capturing by value might be especially important for async invocation, paraller processing.
Using attribute namespaces without repetition
| GCC: 7.0 | Clang: 3.9 | MSVC: not yet |
|---|
Other name for this feature was “Using non-standard attributes” in P0028R3 and PDF: P0028R2 (rationale, examples).
Simplifies the case where you want to use multiple attributes, like:
void f(){
[[rpr::kernel, rpr::target(cpu,gpu)]]// repetition
do-task();
}Proposed change:
void f(){
[[using rpr: kernel, target(cpu,gpu)]]
do-task();
}That simplification might help when building tools that automatically translate annotated such code into a different programming models.
Dynamic memory allocation for over-aligned data
| GCC: 7.0 | Clang: 4.0 | MSVC: not yet |
|---|
In the following example:
class alignas(16)float4{
float f[4];
};
float4*p =newfloat4[1000];C++11/14 did not specify any mechanism by which over-aligned data can be dynamically allocated correctly (i.e. respecting the alignment of the data). In the example above, not only is an implementation of C++ not required to allocate properly-aligned memory for the array, for practical purposes it is very nearly required to do the allocation incorrectly.
C++17 fixes that hole by introducing additional memory allocation functions that use align parameter:
void*operatornew(std::size_t, std::align_val_t);
void*operatornew[](std::size_t, std::align_val_t);
voidoperatordelete(void*, std::align_val_t);
voidoperatordelete[](void*, std::align_val_t);
voidoperatordelete(void*, std::size_t, std::align_val_t);
voidoperatordelete[](void*, std::size_t, std::align_val_t);Unary fold expressions and empty parameter packs
| GCC: 6.0 | Clang: 3.9 | MSVC: not yet |
|---|
todo…
__has_include in preprocessor conditionals
| GCC: 5.0 | Clang: yes | MSVC: not yet |
|---|
This feature allows a C++ program to directly, reliably and portably determine whether or not a library header is available for inclusion.
Example: This demonstrates a way to use a library optional facility only if it is available.
#if __has_include(<optional>)
# include <optional>
# define have_optional 1
#elif __has_include(<experimental/optional>)
# include <experimental/optional>
# define have_optional 1
# define experimental_optional 1
#else
# define have_optional 0
#endifTemplate argument deduction for class templates
| GCC: 7.0 | Clang: not yet | MSVC: not yet |
|---|
Before C++17, template deduction worked for functions but not for classes.
For instance, the following code was legal:
void f(std::pair<int,char>);
f(std::make_pair(42,'z'));because std::make_pair is a template function.
But the following wasn’t:
void f(std::pair<int,char>);
f(std::pair(42,'z'));although it is semantically equivalent. This was not legal because std::pair is a template class, and template classes could not apply type deduction in their initialization.
So before C++17 one has to write out the types explicitly, even though this does not add any new information:
void f(std::pair<int,char>);
f(std::pair<int,char>(42,'z'));This is fixed in C++17 where template class constructors can deduce type parameters. The syntax for constructing such template classes is therefore consistent with the syntax for constructing non-template classes.
todo: deduction guides.
Non-type template parameters with auto type
| GCC: 7.0 | Clang: 4.0 | MSVC: not yet |
|---|
todo…
Guaranteed copy elision
| GCC: 7.0 | Clang: 4.0 | MSVC: not yet |
|---|
Articles:
New specification for inheriting constructors (DR1941 et al)
| GCC: 7.0 | Clang: 3.9 | MSVC: not yet |
|---|
todo…
Direct-list-initialization of enumerations
| GCC: 7.0 | Clang: 3.9 | MSVC: not yet |
|---|
Allows to initialize enum class with a fixed underlying type:
enumclassHandle:uint32_t{Invalid=0};
Handle h {42};// OKAllows to create ‘strong types’ that are easy to use…
Stricter expression evaluation order
| GCC: 7.0 | Clang: 4.0 | MSVC: not yet |
|---|
todo…
constexpr lambda expressions
| GCC: 7.0 | Clang: not yet | MSVC: not yet |
|---|
todo…
A 5 min episode of Jason Turner’s C++ Weekly about constexpr lambdas
Differing begin and end types in range-based for
| GCC: 6.0 | Clang: 3.6 | MSVC: 15.0 Preview 5 |
|---|
Changing the definition of range based for from:
{
auto&& __range =for-range-initializer;
for(auto __begin = begin-expr,
__end = end-expr;
__begin != __end;
++__begin ){
for-range-declaration =*__begin;
statement
}
}Into:
{
auto&& __range =for-range-initializer;
auto __begin = begin-expr;
auto __end = end-expr;
for(; __begin != __end;++__begin ){
for-range-declaration =*__begin;
statement
}
}Types of __begin and __end might be different; only the comparison operator is required. This little change allows Range TS users a better experience.
[[fallthrough]] attribute
| GCC: 7.0 | Clang: 3.9 | MSVC: 15.0 Preview 4 |
|---|
Indicates that a fallthrough in a switch statement is intentional and a warning should not be issued for it. More details in P0068R0.
switch(c){
case'a':
f();// Warning emitted, fallthrough is perhaps a programmer error
case'b':
g();
[[fallthrough]];// Warning suppressed, fallthrough is intentional
case'c':
h();
}[[nodiscard]] attribute
| GCC: 7.0 | Clang: 3.9 | MSVC: not yet |
|---|
[[nodiscard]] is used to stress that the return value of a function is not to be discarded, on pain of a compiler warning. More details in P0068R0.
[[nodiscard]]int foo();
void bar(){
foo();// Warning emitted, return value of a nodiscard function is discarded
}This attribute can also be applied to types in order to mark all functions which return that type as [[nodiscard]]:
[[nodiscard]]structDoNotThrowMeAway{};
DoNotThrowMeAway i_promise();
void oops(){
i_promise();// Warning emitted, return value of a nodiscard function is discarded
}[A 4 min video about [[nodiscard]] in Jason Turner’s C++ Weekly](https://www.youtube.com/watch?v=l_5PF3GQLKc)
[[maybe_unused]] attribute
| GCC: 7.0 | Clang: 3.9 | MSVC: not yet |
|---|
Suppresses compiler warnings about unused entities when they are declared with [[maybe_unused]]. More details in P0068R0.
staticvoid impl1(){...}// Compilers may warn about this
[[maybe_unused]]staticvoid impl2(){...}// Warning suppressed
void foo(){
int x =42;// Compilers may warn about this
[[maybe_unused]]int y =42;// Warning suppressed
}[A 3 min video about [[maybe_unused]] in Jason Turner’s C++ Weekly](https://www.youtube.com/watch?v=WSPmNL9834U)
Ignore unknown attributes
| GCC: Yes | Clang: 3.9 | MSVC: not yet |
|---|
Clarifies that implementations should ignore any attribute namespaces which they do not support, as this used to be unspecified. More details in P0283R1.
//compilers which don't support MyCompilerSpecificNamespace will ignore this attribute
[[MyCompilerSpecificNamespace::do_special_thing]]
void foo();Pack expansions in using-declarations
| GCC: 7.0 | Clang: 4.0 | MSVC: not yet |
|---|
Allows you to inject names with using-declarations from all types in a parameter pack.
In order to expose operator() from all base classes in a variadic template, we used to have to resort to recursion:
template<typename T,typename...Ts>
structOverloader: T,Overloader<Ts...>{
using T::operator();
usingOverloader<Ts...>::operator();
// […]
};
template<typename T>structOverloader<T>: T {
using T::operator();
};Now we can simply expand the parameter pack in the using-declaration:
template<typename...Ts>
structOverloader:Ts...{
usingTs::operator()...;
// […]
};Remarks
- Implemented in GCC 7.0, see this change.
Decomposition declarations
| GCC: 7.0 | Clang: 4.0 | MSVC: not yet |
|---|
Helps when using tuples as a return type. It will automatically create variables and tie them. More details in P0144R0. Was originally called “structured bindings”.
For example:
std::tie(a, b, c)= tuple;// a, b, c need to be declared firstNow we can write:
auto[ a, b, c ]= tuple;Such expressions also work on structs, pairs, and arrays.
Articles:
- Steve Lorimer, C++17 Structured Bindings
- jrb-programming, Emulating C++17 Structured Bindings in C++14
- Simon Brand, Adding C++17 decomposition declaration support to your classes
Hexadecimal floating-point literals
| GCC: 3.0 | Clang: Yes | MSVC: not yet |
|---|
Allows to express some special floating point values, for example, the smallest normal IEEE-754 single precision value is readily written as 0x1.0p-126.
init-statements for if and switch
| GCC: 7.0 | Clang: 3.9 | MSVC: not yet |
|---|
New versions of the if and switch statements for C++: if (init; condition) and switch (init; condition).
This should simplify the code. For example, previously you had to write:
{
auto val =GetValue();
if(val)
// on success
else
// on false...
}Look, that val has a separate scope, without it it will ‘leak’.
Now you can write:
if(auto val =GetValue(); val)
// on success
else
// on false... val is visible only inside the if and else statements, so it doesn’t ‘leak’.
Inline variables
| GCC: 7.0 | Clang: 3.9 | MSVC: not yet |
|---|
Previously only methods/functions could be specified as inline, now you can do the same with variables, inside a header file.
A variable declared inline has the same semantics as a function declared inline: it can be defined, identically, in multiple translation units, must be defined in every translation unit in which it is used, and the behavior of the program is as if there is exactly one variable.
structMyClass
{
staticconstint sValue;
};
inlineintconstMyClass::sValue =777;Or even:
structMyClass
{
inlinestaticconstint sValue =777;
};Articles
DR: Matching of template template-arguments excludes compatible templates
| GCC: 7.0 | Clang: 4.0 | MSVC: not yet |
|---|
This feature resolves Core issue CWG 150.
From the paper:
This paper allows a template template-parameter to bind to a template argument whenever the template parameter is at least as specialized as the template argument. This implies that any template argument list that can legitimately be applied to the template template-parameter is also applicable to the argument template.
Example:
template<template<int>class>void FI();
template<template<auto>class>void FA();
template<auto>struct SA {/* ... */};
template<int>struct SI {/* ... */};
FI<SA>();// OK; error before this paper
FA<SI>();// error
template<template<typename>class>void FD();
template<typename,typename=int>struct SD {/* ... */};
FD<SD>();// OK; error before this paper (CWG 150)(Some useful example needed, since it’s a bit vague to me).
std::uncaught_exceptions()
| GCC: 6.0 | Clang: 3.7 | MSVC: 14.0 |
|---|
More background in the original paper: PDF: N4152 and GOTW issue 47: Uncaught Exceptions.
The function returns the number of uncaught exception objects in the current thread.
This might be useful when implementing proper Scope Guards that works also during stack unwinding.
A type that wants to know whether its destructor is being run to unwind this object can query uncaught_exceptions
in its constructor and store the result, then query uncaught_exceptions again in its destructor; if the result is different,
then this destructor is being invoked as part of stack unwinding due to a new exception that was thrown later than the object’s construction
The above quote comes from PDF: N4152.
constexpr if-statements
| GCC: 7.0 | Clang: 3.9 | MSVC: not yet |
|---|
The static-if for C++! This allows you to discard branches of an if statement at compile-time based on a constant expression condition.
ifconstexpr(cond)
statement1;// Discarded if cond is false
else
statement2;// Discarded if cond is trueThis removes a lot of the necessity for tag dispatching and SFINAE:
SFINAE
template<typename T, std::enable_if_t<std::is_arithmetic<T>{}>*=nullptr>
auto get_value(T t){/*...*/}
template<typename T, std::enable_if_t<!std::is_arithmetic<T>{}>*=nullptr>
auto get_value(T t){/*...*/}Tag dispatching
template<typename T>
auto get_value(T t, std::true_type){/*...*/}
template<typename T>
auto get_value(T t, std::false_type){/*...*/}
template<typename T>
auto get_value(T t){
return get_value(t, std::is_arithmetic<T>{});
}if constexpr
template<typename T>
auto get_value(T t){
ifconstexpr(std::is_arithmetic_v<T>){
//...
}
else{
//...
}
}Articles:
- LoopPerfect Blog, C++17 vs C++14 - Round 1 - if-constexpr
- SO: constexpr if and static_assert
- Simon Brand: Simplifying templates and #ifdefs with if constexpr
Library Features
To get more details about library implementation I suggest those links:
- VS 2015 Update 2’s STL is C++17-so-far Feature Complete - Jan 2016
- libstdc++, C++ 201z status
- libc++ C++1z Status
This section only mentions some of the most important parts of library changes, it would be too impractical to go into details of every little change.
Merged: The Library Fundamentals 1 TS (most parts)
We get the following items:
- Tuples - Calling a function with a tuple of arguments
- Functional Objects - Searchers
- Optional objects
- Class any
- string_view
- Memory:
- Algorithms:
The wording from those components comes from Library Fundamentals V2 to ensure the wording includes the latest corrections.
Resources:
Merged: The Parallelism TS, a.k.a. “Parallel STL.”,
Merged: File System TS,
Merged: The Mathematical Special Functions IS,
Improving std::pair and std::tuple
std::shared_mutex (untimed)
Variant
Splicing Maps and Sets
From Herb Sutter, Oulu trip report:
You will now be able to directly move internal nodes from one node-based container directly into another container of the same type. Why is that important? Because it guarantees no memory allocation overhead, no copying of keys or values, and even no exceptions if the container’s comparison function doesn’t throw.
Contributors
This is a place for you to be mentioned!
Contributors: